Need for Adverse Reaction Knowledgebase
Adverse drug reactions (ADRs) cause a significant burden on healthcare globally. In a relatively small cohort of 1 million patients in primary care, the prevalence of ADRs is around 8.3%. The etiology of ADRs in specific individuals or populations isage, comorbid conditions, genetic predisposition, sex, etc. Interesting case reports of ADRs, drug-drug interactions, genetic associations, clinical trial studies, and electronic health record systems are primary sources of information about drug reactions. Secondary sources include scholarly review articles, curated databases (e.g., LiverTox, UpToDate, Cochrane reviews, PharmaGKB, Comparative Toxicogenomics Database (CTD), Federal adverse event reporting system (FAERS), Offsides, Side Effect Resource (SIDER), etc.), and metadatabases (e.g., Meta adverse drug event database: MetaADEDB). All these sources are essential to understand ADRs and drug-drug interactions caused by pharmaceutical compounds.
So far, developed resources that report ADRs and their association with various factors are either end products of the bioinformatics pipeline or extensive human curation. A typical bioinformatics pipeline generates a long list of drugs that may cause an adverse reaction. On the other hand, human-curated resources include detailed summaries and actionable information for use in healthcare. Although the output of human efforts is less than a few hundred, the reliability and usability of the bioinformatics approach are limited.
With recent advances in natural language processing methods, machines have demonstrated their ability to comprehend natural language like humans. Recently, these natural language processing (NLP) methods showed at-par performance with humans for several natural language tasks such as translation, entity identification, text classification, and comprehension. Nucleati recognizes the potential of advances in these areas and uses NLP to bridge the gap between superficial scratching of published articles by bioinformatics methods and the extensive reliability of human efforts. (Koroteev, 2021)
To demonstrate the potential of the Nucleati codebase and NLP pipeline in intelligent mining of healthcare literature and systematic collection of evidence for evidence-based medicine, we develop the first-of-its-kind, publicly accessible Adverse Drug Reactions Knowledge Base. The knowledge base is 100% curated using Nucleati's artificial intelligence (AI) literature mining robot. It serves as an example of superior reliability and in-depth data mining of articles than the typical bioinformatics method at a scale greater than human curation efforts.
How did we create Adverse Reaction Knowledgebase?
Text classification model
There are nearly 31 million articles available in NCBI PubMed. The number of articles reporting a patient who developed side effects are on the order of a few thousand at best. The first step of knowledge discovery is finding this relatively negligible number of articles from PubMed programmatically. To do so, we generate a training set for every set of articles of interest and train AI models to identify them correctly. A typical model takes 400–500 articles of interest and 10–20k background articles. Once the model is ready, we scan all abstracts available in PubMed to identify relevant articles.
Entity recognition models
Using the transfer learning principles, a general-purpose language model, BERT, is refined using a training set for entity recognition developed by Nucleati. Unlike general-purpose entity recognition models, the models developed in this manner are domain experts. Because the purpose is to identify relevant entities from a focused set of articles, they efficiently recognize them.
Ontology mapping, validation, and term normalization
Unless they are mapped to an ontology or normalized, the identified terms carry little meaning. Nucleati uses a meta thesaurus for mapping terms to ontology. For entities that are irrelevant for ontology mapping, proprietary methods developed by Nucleati are used to validate and normalize various entities.
The adverse reaction knowledge base comprises knowledge across four domains: (1) case reports of ADRs, (2) safety and efficacy studies, (3) genetic predisposition leading to ADRs, and (4) case reports of adverse reactions due to drug-drug interactions. Four text classification and entity recognition models with around ten normalizers empower AI-based knowledge generation.
The user interface
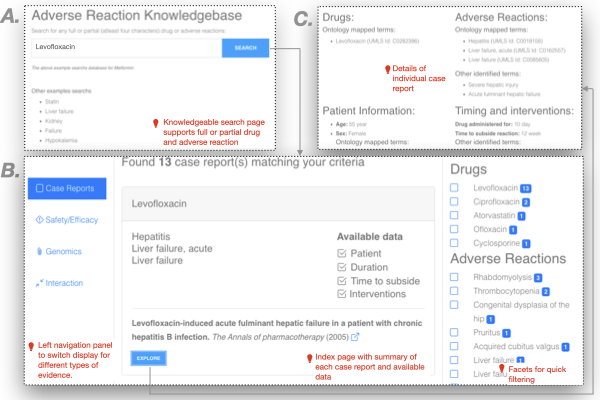
The following snapshot describes various components of the Adverse Reaction Knowledge base user interface. Broadly, the entire UI consists of three main parts: (1) search page, (2) index page, and (3) details of individual AI curated reports. The search page supports searching the database using full or partial drug or adverse reactions. The middle panel of the index page summarizes all hits for a given category of data. The left navigation panel provides a way to switch between different categories of data (evidence). Based on the category of data, the index page provides an easy way to filter the retrieved hits using facets. In addition to providing a basic summary, the index page also notes what type of data is collected using the AI. More details of each identified hit are available through the “Explore” button associated with each result. More details are available only to authenticated users.
Summary and future outlook
Nucleati aims to continue efforts to develop and make AI-curated data available in the field where it is most necessary. One of the immediate interests is identifying and curating case studies, case series, case-control data in genetic medicine, and therapeutic interventions such as CART/Fecal transplantation. We also plan to collect and use AI to curate data for evidence regarding pediatric diseases and interventions.